Видео с ютуба Inference-Heavy Ai Workloads

AI Inference: The Secret to AI's Superpowers

Почему делать логические выводы сложно...

Enterprise inference bottleneck isn’t GPUs — it’s utilization

What is AI Inference?

Showroom EP07: Short-Depth Edge AI Servers - Enabling Heavy AI Workloads for Edge Infrastructure

Hard-Won Lessons from Teams Running High Volume Inference Workloads in Production

ISO-Bench: Can Coding Agents Optimize Real-World Inference Workloads?

Почему вывод LLM обходится дороже, чем обучение (и как это исправить)

Выбор графического процессора для реальных задач ИИ | Пакеты и протоколы #2
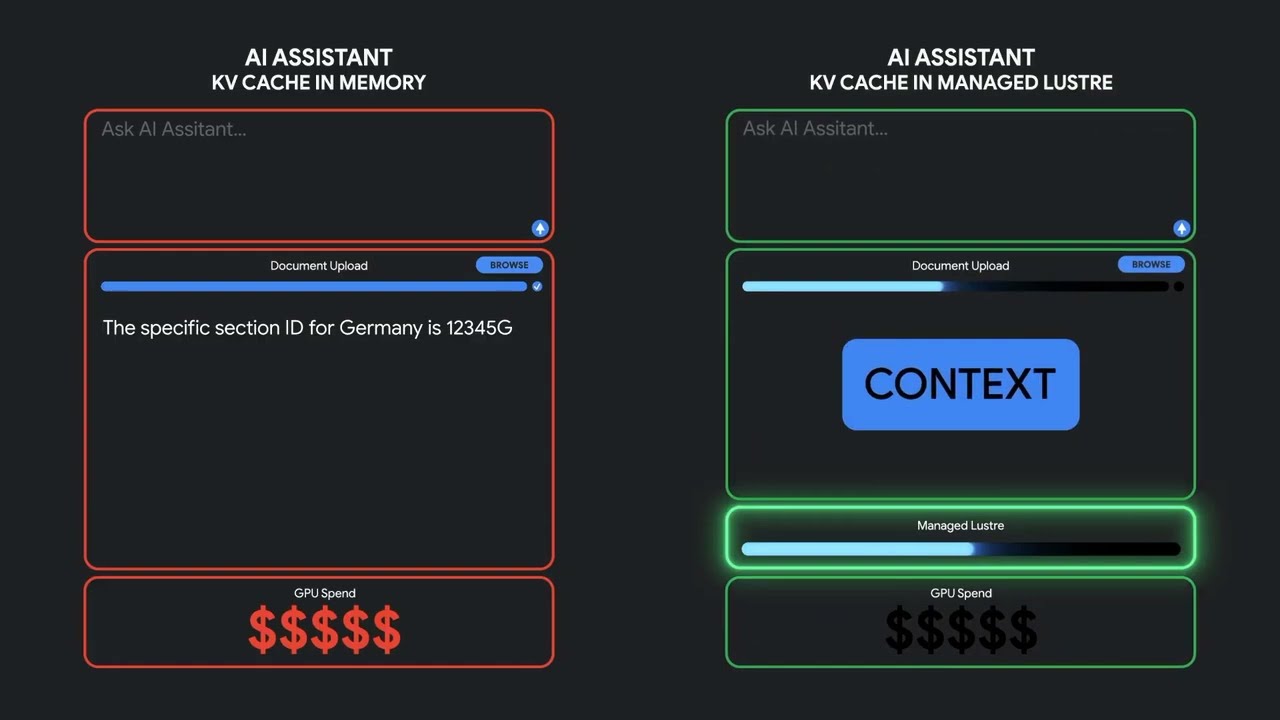
Google Cloud Managed Lustre for LLM Inference: Cut GPU Waste by 50%

Tiered Storage for AI Workloads | Open Storage Summit 2025

fal.ai 2026: Самая быстрая платформа для генеративного искусственного интеллекта

Scaling Production LLM Inference Using EKS Auto Mode & Ray Serve | Ray Summit 2025

Будущее инфраструктуры ИИ: почему одного чипа уже недостаточно

Which GPU is Best for AI Inferencing in 2025?

OpenClaw, вывод результатов, фабрики ИИ: чему мы научились на NVIDIA GTC 2026

Building a Production-Grade AI/ML Inference Platform on Kubernetes, Liad Drori

Stress-testing networks for AI workloads

Cerebras CEO on Delivering AI Inference at Scale

AI Workloads are Reshaping Storage Design and Operational Models